Glueのdynamicframeの内容をCloudwatch logsに載せる(前編)

目次
はじめに
こんにちは。スカイアーチHRソリューションズのmikaです。
今回は(自分の失敗経験談を絡めて)
- GlueジョブでData Catalogにデータを書き込みしたが、一部データが挿入されていなかった。
- 元のCSVデータから読み出しを失敗したのか?それともData Catalog書き込み時にデータが欠落したのか?Cloudwatch logsのGlueジョブログから調査する。
・・といった流れの元に、調査で使用したGlueのdynamicframeの内容をCloudwatch logsに載せる方法を紹介します。
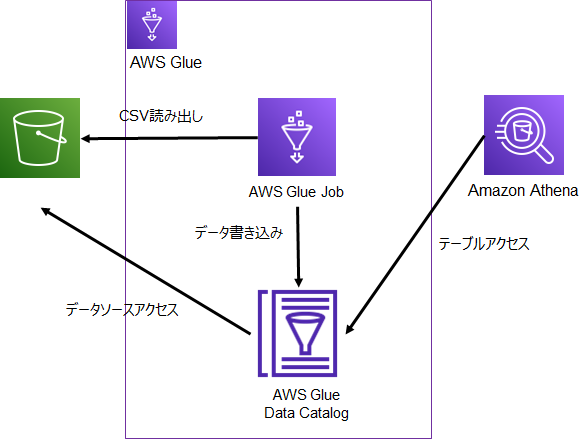
構成
S3バケットに格納したCSVデータをGlueジョブで読み出し、データ型を変換した上でData Catalogに書き込みした後、Athenaより検索することでData Catalogに正しくデータが追加されているかを確認します。
なお、今回S3に格納したCSVデータはこちらになります。
観測所番号,都道府県,日時
11001,北海道,2023/4/1
11016,東京都,2023/4/2
11046,神奈川県,2023/4/3
11061,大阪府,2023/4/4
11076,京都府,2023/4/5
11091,兵庫県,2023/4/6Glueジョブスクリプトで行っていること
Glueジョブ内のスクリプト全文はこちらになります。
・CSVデータ格納場所:s3://<S3バケットのURL>/<CSV格納フォルダ>/<CSV データファイル名>.csv
・Data Catalogデータベース指定:database=”<Data Catalogデータベース名>”
・Data Catalogテーブル指定:table_name=”<Data Catalogテーブル名>”
については、適宜名前を指定してください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node S3 bucket
S3bucket_node1 = glueContext.create_dynamic_frame.from_options(
format_options={
"quoteChar": '"',
"withHeader": True,
"separator": ",",
"optimizePerformance": False,
},
connection_type="s3",
format="csv",
connection_options={
"paths": [
"s3://<S3バケットのURL>/<CSV格納フォルダ>/<CSVデータファイル名>.csv"
],
"recurse": True,
},
transformation_ctx="S3bucket_node1",
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("観測所番号", "string", "観測所番号", "string"),
("都道府県", "string", "都道府県", "string"),
("日時", "string", "日時", "timestamp"),
],
transformation_ctx="ApplyMapping_node2",
)
# Script generated for node Data Catalog table
DataCatalogtable_node3 = glueContext.write_dynamic_frame.from_catalog(
frame=ApplyMapping_node2,
database="<Data Catalogデータベース名>",
table_name="<Data Catalogテーブル名>",
transformation_ctx="DataCatalogtable_node3",
)
job.commit()このうち「S3バケットに格納したCSVデータをGlueジョブで読み出し」を実行している箇所はこちら。create_dynamic_frame.from_optionsにて、S3バケット上のCSVデータを取得します。
# Script generated for node S3 bucket
S3bucket_node1 = glueContext.create_dynamic_frame.from_options(
format_options={
"quoteChar": '"',
"withHeader": True,
"separator": ",",
"optimizePerformance": False,
},
connection_type="s3",
format="csv",
connection_options={
"paths": [
"s3://<S3バケットのURL>/<CSV格納フォルダ>/<CSVデータファイル名>.csv"
],
"recurse": True,
},
transformation_ctx="S3bucket_node1",
)「データ型を変換した上で」を実行している箇所はこちら。ApplyMappingにて、元のCSVデータのデータ型を変換しています。
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("観測所番号", "string", "観測所番号", "string"),
("都道府県", "string", "都道府県", "string"),
("日時", "string", "日時", "timestamp"),
],
transformation_ctx="ApplyMapping_node2",
)最後に「Data Catalogに書き込み」を実行している箇所はこちらになります。write_dynamic_frame.from_catalogにて、Data Catalogにデータ型変換済のデータを書き込みします。
# Script generated for node Data Catalog table
DataCatalogtable_node3 = glueContext.write_dynamic_frame.from_catalog(
frame=ApplyMapping_node2,
database="<Data Catalogデータベース名>",
table_name="<Data Catalogテーブル名>",
transformation_ctx="DataCatalogtable_node3",
)Glueジョブを実行してAthenaで検索
Glueジョブ(本編ではジョブ名「pre1h00_rct」)を実行し、正常終了しました。早速Athenaで検索してみましょう。
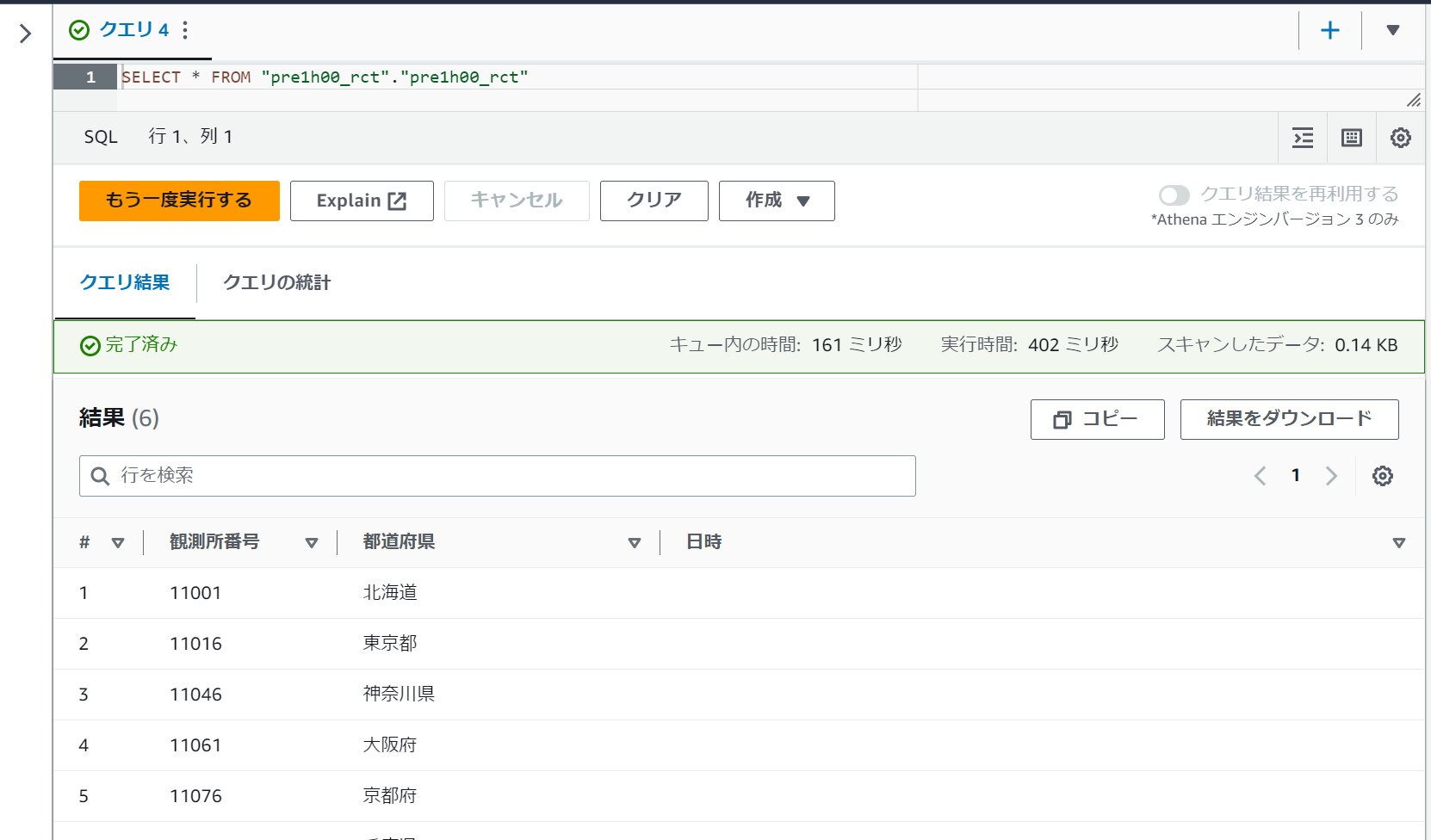
AthenaよりSelect文で全データを検索したところ・・「日時」データが挿入されていません!元のCSVにもちゃんとデータは入っていたし、どこでデータが欠落したのでしょうか?
Glueジョブ実行ログについて
Glueジョブ詳細画面にて「Cloudwatch logs」のリンクをクリックすると、ジョブ実行ログ画面に遷移します。
今回ジョブ自体はエラー無く終了しているので「Output logs」を選択します。
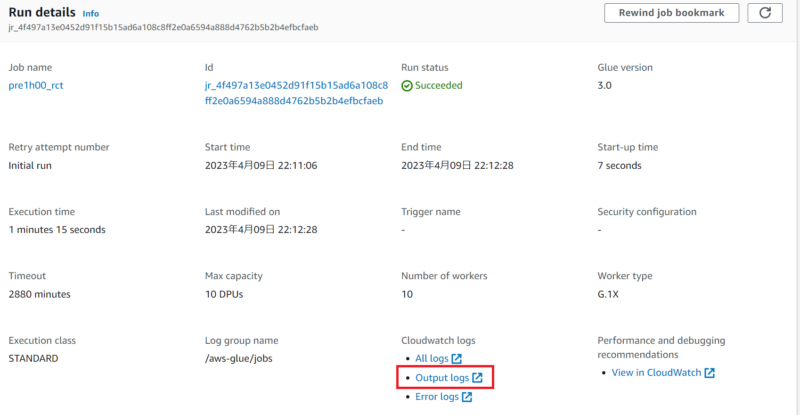
しかしながら有用な情報は得られませんでした。各処理でdynamicframeで実際に取得したテーブル情報が知りたいですね。

Glueのdynamicframeの内容をCloudwatch logsに載せる
Cloudwatch logsの「Output logs」にdynamicframeで実際に取得したテーブル情報を載せるには、Glueジョブスクリプト内に.toDF().show(truncate=False)の一文を追加します。
まずは「S3バケットに格納したCSVデータをGlueジョブで読み出し」実行箇所の最後に
<transformation_ctxで指定した名前>.toDF().show(truncate=False)を、追加します。本編ではtransformation_ctxで指定した名前は「S3bucket_node1」ですので、S3bucket_node1.toDF().show(truncate=False)の一文を追加しています。
# Script generated for node S3 bucket
S3bucket_node1 = glueContext.create_dynamic_frame.from_options(
format_options={
"quoteChar": '"',
"withHeader": True,
"separator": ",",
"optimizePerformance": False,
},
connection_type="s3",
format="csv",
connection_options={
"paths": [
"s3://<S3バケットのURL>/<CSV格納フォルダ>/<CSVデータファイル名>.csv"
],
"recurse": True,
},
transformation_ctx="S3bucket_node1",
)
S3bucket_node1.toDF().show(truncate=False)また、「データ型を変換した上で」実行箇所にも追加します。元のCSVから正しくデータ取得しているのに、ApplyMappingによるデータ型変換で失敗している可能性もあるからです。
本編ではtransformation_ctxで指定した名前は「ApplyMapping_node2」ですので、ApplyMapping_node2.toDF().show(truncate=False)の一文を追加しています。
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("観測所番号", "string", "観測所番号", "string"),
("都道府県", "string", "都道府県", "string"),
("日時", "string", "日時", "timestamp"),
],
transformation_ctx="ApplyMapping_node2",
)
ApplyMapping_node2.toDF().show(truncate=False)後編予告
Glueのdynamicframeの内容をCloudwatch logsに載せる(後編)では、dynamicframeで実際に取得したテーブル情報を載せたCloudwatch logsの「Output logs」を確認し、データがどこで欠落しているかを突き止めます。

関連記事
-
Glueのdynamicframeの内容をCloudwatch logsに載せる(後編)
-
 CloudWatch Logs + Lambda + SNSでEC2のログ監視を実装してみよう
CloudWatch Logs + Lambda + SNSでEC2のログ監視を実装してみよう -
 LambdaとCloudWatch Logsを使ったジョブの遅延監視を考えてみる
LambdaとCloudWatch Logsを使ったジョブの遅延監視を考えてみる