Glueのdynamicframeの内容をCloudwatch logsに載せる(後編)

目次
前編のおさらい
こんにちは。スカイアーチHRソリューションズのmikaです。
本記事は、Glueのdynamicframeの内容をCloudwatch logsに載せる(前編)の続きです。
前編ではGlueジョブにて「S3バケットに格納したCSVデータをGlueジョブで読み出し、データ型を変換した上でData Catalogに書き込み」を行い、Athenaより検索することでData Catalogに正しくデータが追加されているかを確認しました。
・・ところが、一部のデータ(日時データ)が挿入されていませんでした!
後編では、dynamicframeで実際に取得したテーブル情報を載せたCloudwatch logsの「Output logs」を確認し、データがどこで欠落しているかを突き止めます。
dynamicframeの内容が載ったCloudwatch logsを確認する
Glueジョブスクリプト内に.toDF().show(truncate=False)の一文を追加し、ジョブを再実行して「Output logs」を確認します。
お、何だかログの行数が増えていますね。テーブルヘッダらしきものもチラ見えしています。
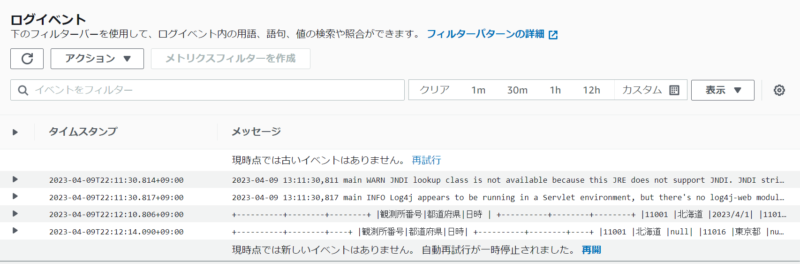
まずは「S3バケットに格納したCSVデータをGlueジョブで読み出し」実行直後のテーブル情報を確認します。全データ問題なく取得出来ていますね。
+----------+--------+--------+
|観測所番号|都道府県|日時 |
+----------+--------+--------+
|11001 |北海道 |2023/4/1|
|11016 |東京都 |2023/4/2|
|11046 |神奈川県|2023/4/3|
|11061 |大阪府 |2023/4/4|
|11076 |京都府 |2023/4/5|
|11091 |兵庫県 |2023/4/6|
+----------+--------+--------+続いて「データ型を変換した上で」実行直後のテーブル情報を確認・・ここで日時データが「null」になっていました!つまりApplyMapping処理時に何らかの理由でデータが欠落したということですね。
+----------+--------+----+
|観測所番号|都道府県|日時|
+----------+--------+----+
|11001 |北海道 |null|
|11016 |東京都 |null|
|11046 |神奈川県|null|
|11061 |大阪府 |null|
|11076 |京都府 |null|
|11091 |兵庫県 |null|
+----------+--------+----+ApplyMapping時にデータが欠落した原因
Glueジョブスクリプト内ではApplyMappingにて元のCSVデータのデータ型を変換しています。
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("観測所番号", "string", "観測所番号", "string"),
("都道府県", "string", "都道府県", "string"),
("日時", "string", "日時", "timestamp"),
],
transformation_ctx="ApplyMapping_node2",
)
ApplyMapping_node2.toDF().show(truncate=False)日時データはtimestamp型に変換しているのですが、スラッシュ(/)区切りの日付形式はApplyMappingで対応出来ない形式だったのです。そのため日時データだけ欠落してしまいました。
従ってCSVの日付形式をスラッシュ(/)区切りからハイフン(-)区切りに変更し、S3に再配置します。
観測所番号,都道府県,日時
11001,北海道,2023-4-1
11016,東京都,2023-4-2
11046,神奈川県,2023-4-3
11061,大阪府,2023-4-4
11076,京都府,2023-4-5
11091,兵庫県,2023-4-6なお日付形式をスラッシュ(/)区切りのままで使用したい場合は、弊社グループのエンジニアが書いた記事がありますのでそちらを参考にしてください。
再度Glueジョブ実行/Cloudwatch logs確認、Athena検索
S3バケットに修正したCSVを格納し、再度Glueジョブを実行して「Output logs」を確認します。
「S3バケットに格納したCSVデータをGlueジョブで読み出し」実行直後のテーブル情報/「データ型を変換した上で」実行直後のテーブル情報共にデータが入っていました。
「Output logs」内の「S3バケットに格納したCSVデータをGlueジョブで読み出し」実行直後のテーブル情報
+----------+--------+--------+
|観測所番号|都道府県|日時 |
+----------+--------+--------+
|11001 |北海道 |2023-4-1|
|11016 |東京都 |2023-4-2|
|11046 |神奈川県|2023-4-3|
|11061 |大阪府 |2023-4-4|
|11076 |京都府 |2023-4-5|
|11091 |兵庫県 |2023-4-6|
+----------+--------+--------+「Output logs」内の「データ型を変換した上で」実行直後のテーブル情報
+----------+--------+-------------------+
|観測所番号|都道府県|日時 |
+----------+--------+-------------------+
|11001 |北海道 |2023-04-01 00:00:00|
|11016 |東京都 |2023-04-02 00:00:00|
|11046 |神奈川県|2023-04-03 00:00:00|
|11061 |大阪府 |2023-04-04 00:00:00|
|11076 |京都府 |2023-04-05 00:00:00|
|11091 |兵庫県 |2023-04-06 00:00:00|
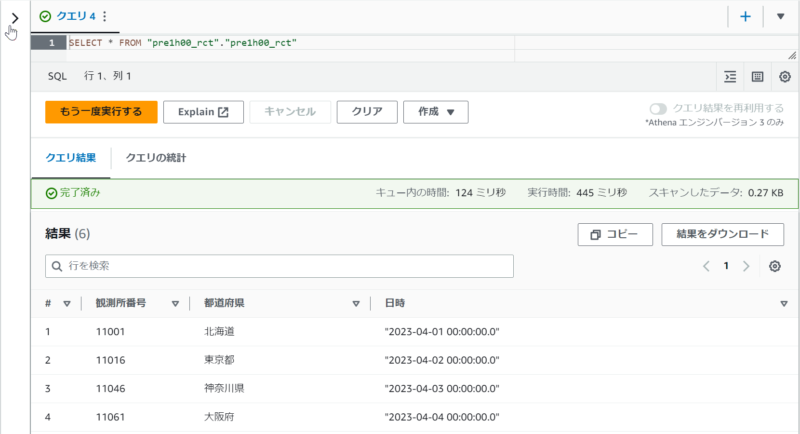
+----------+--------+-------------------+Athenaでも再度Select文で検索してみます。今度は日時データも挿入されていました。
おわりに
今回はGlueのdynamicframeの内容をCloudwatch logsに載せる方法を紹介しました。
Glueジョブ自体は正常終了したにもかかわらず、本編のように実際はデータが欠落しテーブルに入らなかったり等、ジョブ実行結果が想定通りにならないことが多々あります。調査方法としてログ解析が重要になって来るのですが、ログの情報が不足しているケースも良くありがちです。
その際、ログ内容を充実させる方法の一つとして参考になれば幸いです。いち早くトラブル解決しましょう!

関連記事
-
Glueのdynamicframeの内容をCloudwatch logsに載せる(前編)
-
 CloudWatch Logs + Lambda + SNSでEC2のログ監視を実装してみよう
CloudWatch Logs + Lambda + SNSでEC2のログ監視を実装してみよう -
 LambdaとCloudWatch Logsを使ったジョブの遅延監視を考えてみる
LambdaとCloudWatch Logsを使ったジョブの遅延監視を考えてみる