オートスケールするRDSのストレージ容量を監視したい

目次
はじめに
こんにちは、CloudBuildersのsugawaraです。
今回はRDSに関する小ネタです。オートスケールを設定をしているRDSでストレージ容量の監視を設定してみました。少し紆余曲折があったので、今回はそれをシェアしたいと思います。
なお、実際に検証するときにはサーバーワークスさんの【CloudWatch】RDSのストレージ使用率を監視してみるを参考にしました。具体的な設定についてはこちらをご参照ください。本記事は、上記記事では言及されていないもっと基礎的な部分の補足という位置づけになります。
RDSのオートスケール
まずはRDSがオートスケールする際の条件や挙動について、簡単におさらいします。
オートスケールの条件と挙動
実際にRDSがオートスケールする条件は下記の3つです。
- 使用可能な空き領域が、割り当てられたストレージの10%未満である。
- 低ストレージ状態が5分以上続いている。
- 最後のストレージ変更、あるいはインスタンスでストレージの最適化が完了してから少なくとも6時間経過している。
そして、ストレージ追加されるのは次のうちでもっとも大きいものになります。
- 10GiB
- 現在割り当てられているストレージの10%
- 今後7時間以内に現在割り当てられているストレージサイズを超えると予測されるストレージ増加分(過去1時間の FreeStorageSpace メトリクスをもとに算出)
なお、オートスケールは拡大のみであり、使っていないからと言って縮小されるようなことはありません。
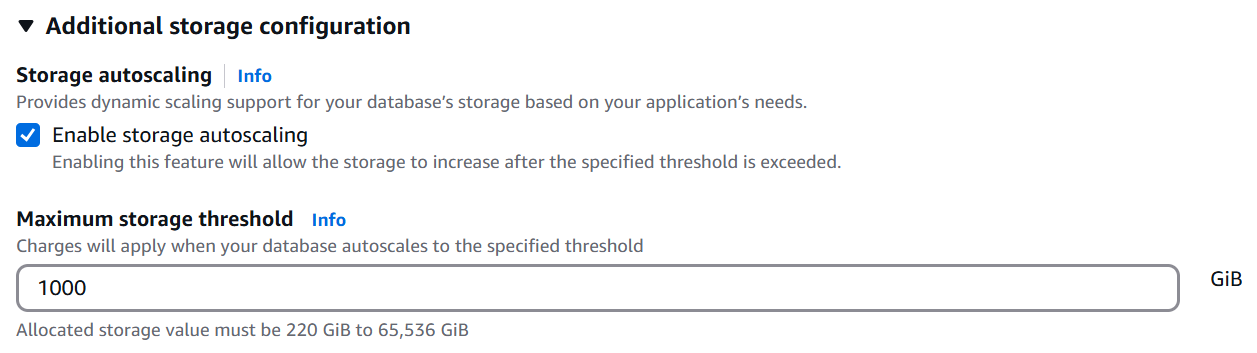
コンソール上でオートスケールの設定する場合、RDS作成時に下記のようにEnable storage autoscalingにチェックをいれて、最大値を指定します。
イベントサブスクリプション
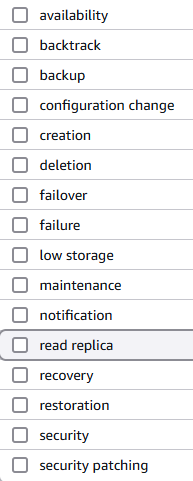
RDSのイベントサブスクリプションを設定することで、RDS関連のリソースで何かしらのイベントが発生した際に、イベント通知をサブスクライブすることができます。今回であれば、オートスケール時にイベント通知が行われます。
他にも下記のような項目に関連するイベントが発生した場合、指定したARN、もしくはSNS Topicに通知します。
実際に設定することで、RDSのオートスケーリングが実行される前と実行された後で、イベントID:RDS-EVENT-0217とRDS-EVENT-0218がイベントサブスクリプションによって通知されます。
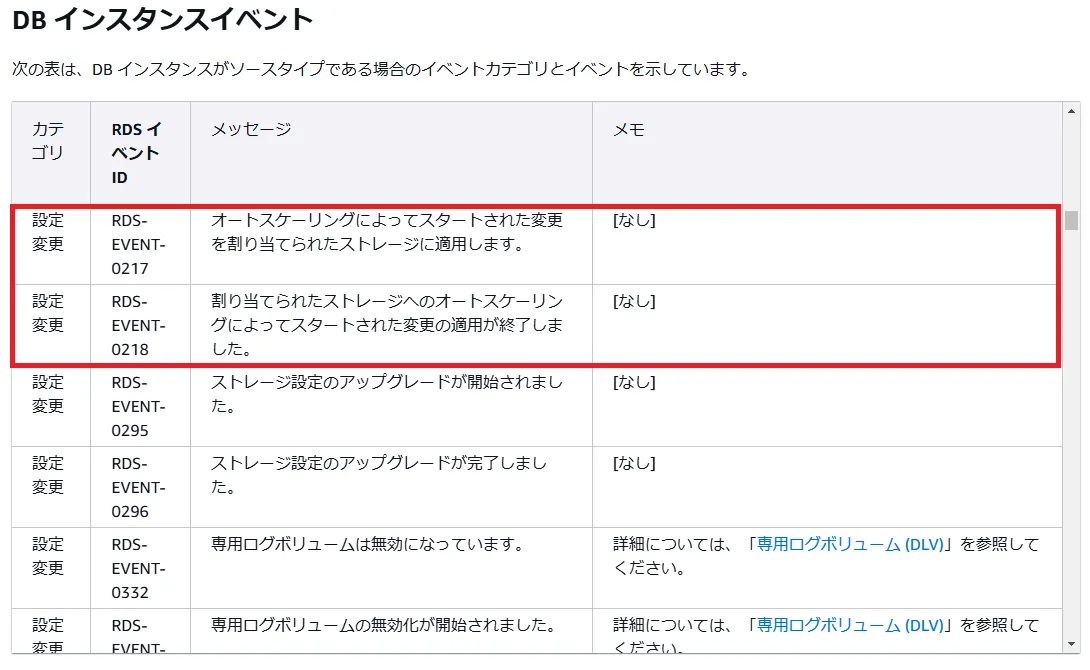
これらのイベント通知により、RDSがオートスケールする/したということが管理者に通知されます。
なお、コンソール上でイベントサブスクリプションの設定をしたい場合、RDSのコンソール画面へ遷移後、左側ペイン下部にあるEvent subscriptionsから設定することができます。
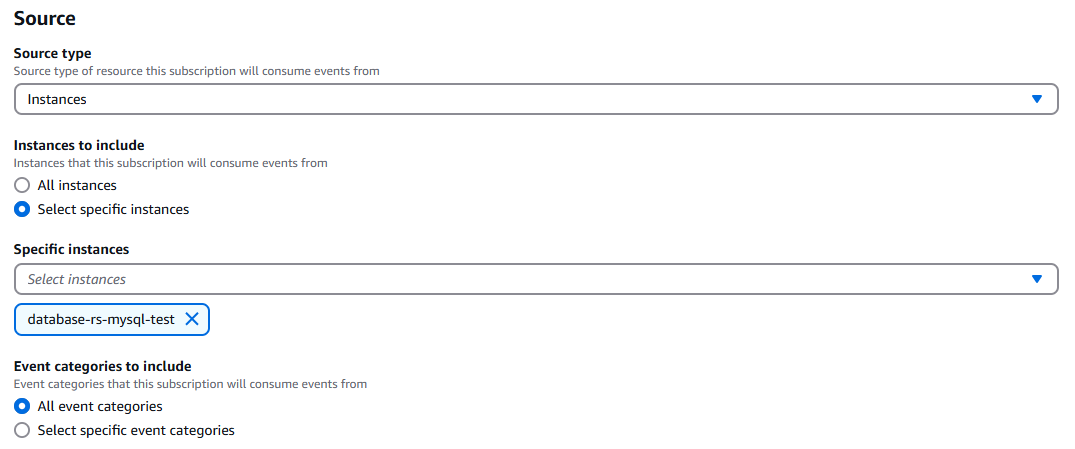
Create event subacriptionのボタンをクリックし、下記のような画面で種類や通知対象を指定します。
RDSストレージ監視におけるオートスケール時の問題点
RDSのオートスケールについておさらいができたところで、本題であるストレージ監視の問題点についてみていきます。
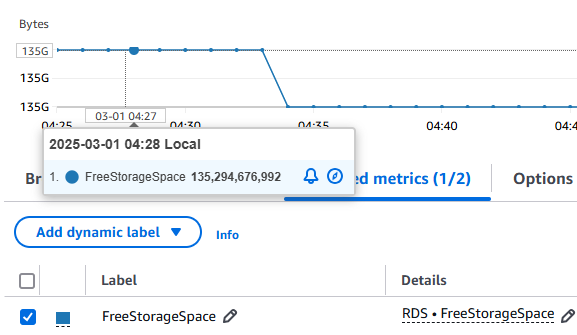
RDSのストレージに関するメトリクスには、FreeStorageSpaceというものがあります。これは「使用可能なストレージ領域の容量」を表すものです。こちらのメトリクスを監視することで、現在の空きストレージ容量を確認することができます。また、CloudWatch Alarmでしきい値を設定すれば、指定したストレージ容量以下になった場合にはアラートメールを飛ばすこともできます。
オートスケールしないRDSであれば、上記の設定をするだけでRDSのストレージ容量の監視ができます。しかし、オートスケールの設定をしている場合、いくつか問題(や面倒ごと)が生じてきます。
- アラームに静的なしきい値を設定する必要がある
- FreeStorageSpaceはバイト表記である
1の静的なしきい値については例で考えてみます。RDSのストレージを100GBで、使用済みストレージ容量が80%超えたらアラートを発報したいと仮定します。つまり、しきい値を20GBに設定する。この設定の状態でオートスケールが実行され、仮に120GBになったとしたら、使用済みストレージ容量80%は24GBなります。したがって、元々の20GBから24GBに変化してズレが生じてしまっています。
また、2にあるようにバイトでしきい値を指定する必要があります。そのため、バイトへの変換計算が必要になることがあります。
アプローチ
オートスケールRDSのストレージ監視では、標準メトリクスのFreeStorageSpaceに静的にしきい値を設定してはダメなので、いくつか考えられるアプローチを考えていました。それが以下の3つです。
- LambdaとEventBridgeを利用してしきい値の書き換え
- Metric Mathを利用してカスタムメトリクスの作成
- 拡張モニタリングで出力されるログにメトリクスフィルターを作成
そもそもイベントサブスクリプションがあるから対応不要
それぞれ簡単に説明していきます。
LambdaとEventBridgeを利用してしきい値の書き換え
EventBridgeとLambdaを用いることで、CloudWatch Alarmのしきい値を書き換える方法です。イベントサブスクリプションなどをトリガーに、アラームのしきい値を書き換えるLambdaを実行します。こちらはStep Functionsでも実装可能だと思われます。このアプローチではそもそもLambdaのコーディングや運用保守、権限周りについて考える必要が生じてしまうため、できればやりたくないものでした。真っ先に思い浮かんだけど、最終手段という位置づけですね。
Metric Mathを利用してカスタムメトリクスの作成
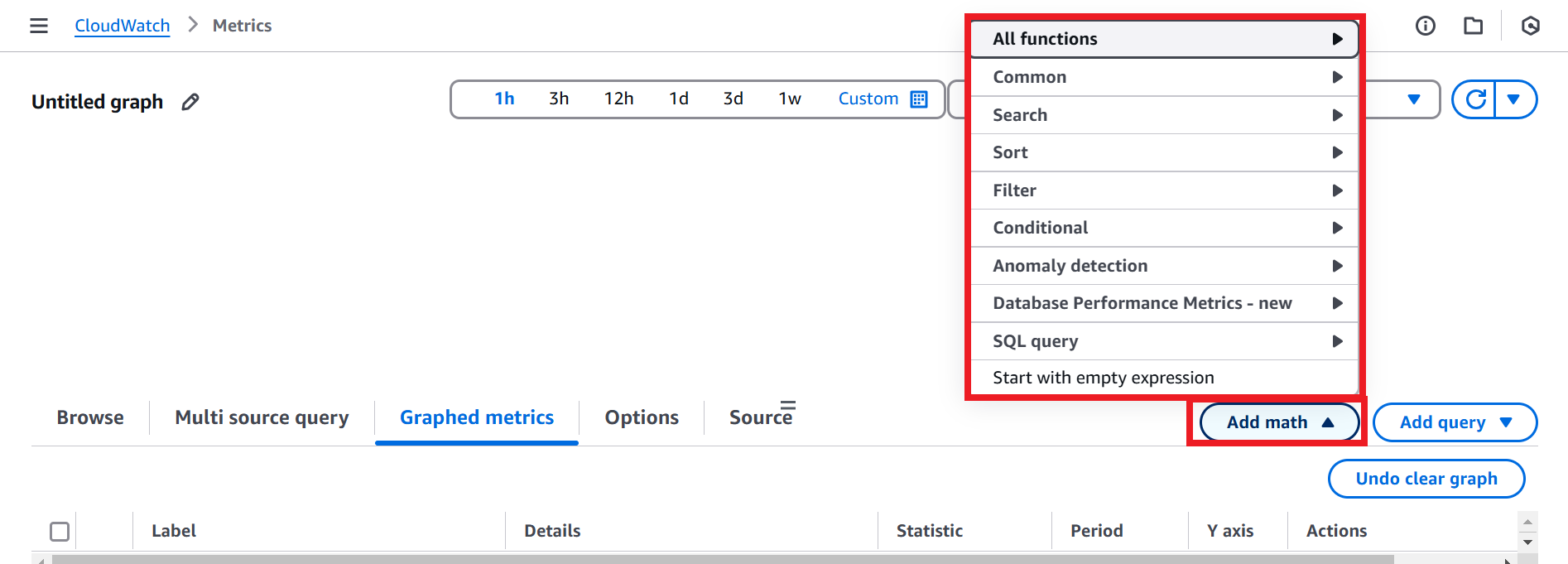
次に考えたのが、CloudWatch MetricsでカスタムメトリクスをMetric Mathを利用して独自に作成する方法です。Metric Mathとは、複数のメトリクスを数式を利用して計算して新たなメトリクスを作成することができる機能です。CloudWatch Metricsの画面にて、add math(数式を追加)から利用したい数式を選択することができます。また、Start with empty expression(空の式で始まる)を選ぶと、自分で一から数式を入力することができます。
今回はRDSのストレージ容量を動的に取得するため、TotalStorageSpaceからFreeStorageSpaceを引き、バイト計算を行うことでどのくらい利用しているかがわかるはずと考えました。
(TotalStorageSpace - FreeStorageSpace) / (1024 * 1024 * 1024)しかし、そもそもTotalStorageSpaceは標準メトリクスでは取得できないため、Lambdaなどを他のサービスと併用せざるを得ないことがわかり、断念しました。欲しいものを独自に編み出すという部分はよかったのですが、その材料になるものが揃わず。もしTotalStorageSpaceもメトリクスが取得できるなら、シンプルに実装できたかもしれません。
拡張モニタリングで出力されるログにメトリクスフィルターを作成
続いて、拡張モニタリングとメトリクスフィルターの併用です。実際、今回はこれを採用しています。
拡張モニタリングとはRDSインスタンスのOSレベルのメトリクスを取得し、より詳細なパフォーマンスデータをリアルタイムで監視できる機能です。デフォルトで、このメトリクスは CloudWatch LogsのRDSOSMetricsというロググループ名で30日間保存されます。
拡張モニタリングを有効化したい場合、RDS作成時にEnable Enhanced monitoringにチェックを入れ、メトリクス取得間隔などを設定します。(なお、作成後も可)

拡張モニタリングを有効化し、メトリクスが収集されると、下記のようなRDSOSMetricsというロググループが自動的に作成されます。

各RDSの拡張モニタリングのメトリクスはRDSOSMetrics内のログストリームにそれぞれ格納されます。したがって、1つのRDSにつき、1つのログストリームという構成になります。下記はRDS for SQL Serverを使用した際のログの例です。不要な箇所は省略しています。disk内のusedPcは使用済み容量のパーセンテージを表しているので、こちらを監視します。あくまでパーセンテージですので、アラームの設定もパーセンテージを指定する必要があります。
{
"engine": "SqlServer",
"instanceID": "XXXXXXXXXX",
"instanceResourceID": "db-QFLBDEX74ADZOUK6DUQLOH75HI",
"timestamp": "2025-02-13T07:19:19Z",
"version": 1,
"uptime": "0 days, 06:24:54",
"numVCPUs": 4,
"cpuUtilization": {
"idle": 99.64,
"kern": 0.16,
"user": 0.21
},
"memory": {
"commitTotKb": 3206896,
"commitLimitKb": 19512856,
"commitPeakKb": 3337920,
"physTotKb": 16498200,
"physAvailKb": 13621852,
"sysCacheKb": 2129880,
"kernTotKb": 991712,
"kernPagedKb": 196828,
"kernNonpagedKb": 794884,
"sqlServerTotKb": 393552,
"pageSize": 4096
},
"system": {
"handles": 31670,
"threads": 1046,
"processes": 57
},
"disks": [
{
"name": "rdsdbdata",
"totalKb": 104724416,
"usedKb": 338304,
"usedPc": 0.32, // ←ここに注目!!
"availKb": 104386112,
"availPc": 99.68,
"rdCountPS": 0,
"rdBytesPS": 0,
"wrCountPS": 0.77,
"wrBytesPS": 4949.33
}
],
"network": [
{
...
}
],なお、利用するデータベースによってログの出力形式が異なります。簡単に言うと、上記のSQL Serverか、それ以外かで分かれるようです。詳細はこちらからご確認ください。
次に、メトリクスフィルターです。メトリクスフィルターとは、CloudWatch Logsに出力されるログを監視し、検索やフィルタリングを可能にする機能です。フィルターパターンを指定することで、ログ内の指定したフィルターパターンから該当するログを取得できます。上記のログであれば、disk内のusedPcを監視します。パーセンテージを用いたアラームを設定して、例えば80%を超えた場合にはアラーム状態にする、などができます。
イベントサブスクリプションのため対応不要
最後のアプローチ(?)は、イベントサブスクリプションで説明したように、空きストレージ容量が少なくなってきた場合にはイベント通知が実行されます。これがあればわざわざ追加でアラームの設定は不要になる可能性があります。本当に監視とアラームが必要かは各プロジェクトで要検討かと思われます。
参考
- 【CloudWatch】RDSのストレージ使用率を監視してみる
- Managing capacity automatically with Amazon RDS storage autoscaling
- Amazon RDS event categories and event messages
- Using math expressions with CloudWatch metrics
- OS metrics in Enhanced Monitoring
おわりに
今回はオートスケールするRDSのストレージ監視について解説しました。具体的な設定方法はすでに存在するため、今回はそれの補足的な内容となっています。
オートスケールのRDSのストレージを監視する際には、拡張モニタリング+メトリクスフィルターというアプローチを検討してみてはいかがでしょうか?

関連記事
-
 Glueのdynamicframeの内容をCloudwatch logsに載せる(後編)
Glueのdynamicframeの内容をCloudwatch logsに載せる(後編) -
 LambdaとCloudWatch Logsを使ったジョブの遅延監視を考えてみる
LambdaとCloudWatch Logsを使ったジョブの遅延監視を考えてみる -
 【Amazon CloudWatch Synthetics Canary】使ってみたけど上手くいかなかった話
【Amazon CloudWatch Synthetics Canary】使ってみたけど上手くいかなかった話